

AIを作ってみよう:消費予測(5/6) までの記事で、AIを作り、精度を上げるためにデータを拡張するといったことをしました。
データの量や種類を増やすほどAIは正確になっていきますが、実はもう少し効率のよい方法があります。それは、最初から重要なデータだけ使うという方法です。
重要なデータだけ使う? そんなことができれば苦労しない! と思いますよね。統計的機械学習には簡単に実行できてしまう命令があります。
この記事では、データの相関性を求め、重要なデータだけ使う方法をお教えします。
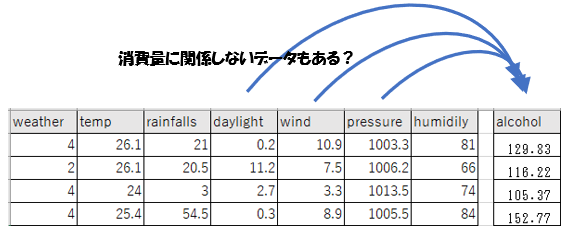
消費量に関係ないデータがある
データの種類は最終的に「天気、気温、雨量、日照時間、気圧、風速、湿度」まで増やしました。ただ、この全てがお酒の消費量に関係するかは分かりませんね。
それをAIに学習してもらっているんですが、もし影響のないデータが分かれば、次回からデータを取得する必要がなくなります。
統計的機械学習には、データの要・不要を判断してくれる計算があります。主成分分析といいます。
一度実行して、次回からデータ収集を簡素化するようにしましょう。
不要なデータを知る方法(主成分分析)
不要なデータは主成分分析という命令ですぐ分かってしまいます。
下記のプログラムをコピペして実行してみてください。
データのほうは、AIを作ってみよう:お酒の消費予測その5でコピペした学習データをそのまま使います。
- 下記のプログラムをコピペして「data-select.py」というファイル名でデスクトップに保存します。
- AIを作ってみよう:お酒の消費予測(5/6)にアクセスし、tenkisake-gakushu-data2.csv をコピペしてこのファイル名で保存し、デスクトップへ置きます。
- プロンプトを開きます。(Windowsの場合は Windowsスタートボタン→「cmd」を実行、Macの場合は Terminalを実行)
- 「cd desktop」を実行します。
- 「python data-select.py」を実行し、数分待ちます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
import numpy as np from sklearn.preprocessing import StandardScaler import pandas as pd from sklearn.decomposition import PCA from sklearn.feature_selection import SelectKBest, f_regression # read data with header all_data = pd.read_csv('tenkisake-gakushu-data2.csv', header=0) features_data = all_data[['weather','temp','rainfalls','daylight','wind','pressure','humidily']].values labels_data = all_data['alcohol'].values # seikika sc = StandardScaler() sc.fit(features_data) features_data = sc.transform(features_data) # True/False selector = SelectKBest(score_func=f_regression, k=4) selector.fit(features_data, labels_data) mask = selector.get_support() print('KBest = ', mask) # kiyoritu% sorted pca = PCA() pca.fit(features_data) print('pca.explained_variance_ratio_ = ', pca.explained_variance_ratio_) |
結果の見方
|
1 2 |
which is good = [True False False False True True True] kiyoritu sorted = [0.33326639 0.19798281 0.15942287 0.11914105 0.09194287 0.06548352 0.03276049] |
結果は少し分かりにくいかもしれませんが解説をします。
1行目は、データの種類「天気、気温、雨量、日照時間、気圧、風速、湿度」のうち結果に強く影響している上位4つをTrueと表示しています。いま下線になっているデータが結果に強く影響しているということです。これは4つ選ぶよう指示したからで、この個数は変えることができます。
2行目は、データ各種が結果にどの程度影響しているかの割合です。ただ順番は強い割合の順に並んでしまっています。最初の0.33は、「天気、気温、雨量、日照時間、気圧、風速、湿度」のうち最も結果に影響するどれかのデータが、データ全体の33%の強さで結果に影響しているという意味です。データのどれを指すかは見えていません。
1、2行目を合わせて解釈すれば、結果に強く影響しているのは、「天気、気圧、風速、湿度」であり、その合計割合は約78%(33+19+15+11)です。一般的には60~80%ぐらいのデータを使うのが良いと言われているので、この4データで予測しても十分だということですね。
もし興味がある人は、データをこの4種類のみに編集し、プログラムを4データのみ使うように改修して実行してみてください。
少しですが結果が改善することがあります。また少しですが計算時間が早くなっています。
次回からは、4つのデータさえ収集すればいいことになりました。また、データが大量になるほど計算時間が短縮できます。
いかがでしたか。
このように、本当に必要なデータというものを分析することで、データ収集の手間が少なくなり、計算時間が早くなるというメリットがあります。扱うデータが大きいほど有効です。