

Udemyで異常検知のコースを開設しました。具体的な実装方法を分かり易く短時間にまとめましたので活用ください。

AIを学んでいると、ログや画像についてはよく扱いますが、音声についてあまり触れないと思います。どう扱うのか想像つきませんね。
実は、Pythonであれば画像と同様、簡単に音声データを解析することができます。以下の内容を知っておけば、今後は音声も分析対象として考えることができ、仕事の幅(ビジネスの幅)が広がると思います。
音声をAIに活用する例
例えばこんなことに音声が使えます。
- 音声認識
発声で人物を特定・認証したり、画像がなく音のみの状況下で何が存在しているか判別することができます。
- 動物や設備の異常検知
家畜の声の異常を検知して健康管理をしたり、機械設備の異常音を検知することで故障を予知するなどが可能です。
- 特定の音がした時のみ機械を作動させる遠隔操作
特定の機械音を発したら街や駅のディスプレイ表示を切り替えるなど遠隔操作ができます。
音声を扱うPython命令
それでは、Pythonで音声データを扱うことができる命令を挙げていきます。
- ライブラリのインストール
音声データの扱いは librosa というライブラリを使います。Pythonインストール済みのLinuxかWindowsで次を実行してください。
|
1 |
pip install librosa |
- 音声データの読み込み
画像を数値の配列として読み込むことができるように、音声も同様のことができます。読込可能なファイル形式は wav, mp3 です。
|
1 2 3 4 |
import librosa y, sr = librosa.load('onsei.wav') # y = 音声データが入る。振幅値が連続したnumpy.array。 # sr = サンプリングレート値(1秒間の音声データ数)が入る。 |
- 音声データの波形を絵画
librosa.loadで呼んだ音声データはSin波のグラフを描くことができます。
|
1 2 3 4 5 |
import librosa import matplotlib.pyplot as plt y, sr = librosa.load('onsei.wav') plt.plot(y) plt.show() |
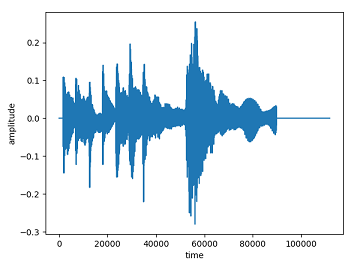
- 振幅の平均値を計算する
音声データ毎に振幅の平均値を計算し、他のデータと比べることによって音に特徴があるか確認することができます。音声データが多数あれば機械学習のデータに使えます。
|
1 2 3 4 |
import librosa import numpy as np y, sr = librosa.load('onsei.wav') y_mean = np.sqrt(np.mean(y=y**2,axis=1)) |
- ゼロクロス数を計算する
ゼロクロス数は雑音の入り具合が分かる数値で、これを音声データ毎に計算し他のデータと比べて特徴がないか見るということをします。音声データが多数あれば機械学習のデータとして使えます。
|
1 2 3 |
import librosa y, sr = librosa.load('onsei.wav') zc = librosa.zero_crossings(y) |
- メルスペクトログラムを計算する
音声波形を複数のsin波に分解し周波数と振幅と時間の情報を持たせ、さらに高音低音で粗さを考慮したデータをメルスペクトログラムといいます。可視化して特徴を見たり、機械学習のデータとして使います。
|
1 2 3 4 5 6 7 8 9 |
import librosa import matplotlib.pyplot as plt y, sr = librosa.load('onsei.wav') melspec = librosa.feature.melspectrogram(y, sr) # 人間が分かる音量にデシベル変換 melspec_db = librosa.amplitude_to_db(melspec) # 可視化 librosa.display.specshow(melspec_db) plt.show() |

機械学習に使う
今回は音声データに対し「振幅の平均値」「ゼロクロス数」「メルスペクトログラム」といった特徴を算出しました。これらを入力(説明変数)として機械学習のデータにすることができます。例えば異常検出プログラムを書くとこのようになります。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
import glob import librosa import numpy as np import matplotlib.pyplot as plt from sklearn import preprocessing # 複数データを読み込み dataset = [] melspecs = [] for file_name in glob.glob('dir/*.wav'): y, sr = librosa.load('onsei.wav') dataset.append(y) # メルスペクトログラムの計算 melspec = librosa.feature.melspectrogram(y, sr) melspec = librosa.amplitude_to_db(melspec).flatten() melspecs.append(melspec.astype(np.float16)) # 各データの振幅の平均値 mean = np.sqrt(np.mean(dataset**2,axis=1)) # 各データのゼロクロス数 zc = np.sum(librosa.zero_crossings(dataset),axis=1) # 機械train_feature学習データにする train_feature = pd.DataFrame() train_feature['mean'] = mean train_feature['zc'] = zc train_feature['melspecs'] = melspecs train_labels = # 正常・異常などを表すラベルを音声データ分入れる # 上記のfeatureで特徴があれば教師あり学習のアルゴリズムを使い、 # なければ教師なし学習で異常検知を狙うとよい。 # アルゴリズムによっては数値の標準化が必要。 # 機械学習:下記例は教師ありのRandomForestを用いている。 from sklearn.ensemble import RandomForestClassifier model = RandomForestClassifier() model.fit(train_feature, train_labels) # 予測 pred = model.predict(test_feature) |
以上、音声データを扱う命令と、機械学習への使い方を書きました。
Pythonを使うと画像も音声も手間は同じですね。音声も予想を行う要素として活用していきましょう。