
別の記事で紹介しているとおり、学習済みのAIをダウンロードすることによって簡単に物体検出などが可能です。
しかし特殊な物体を検出したい場合は、自分でデータを作り学習を行わなければなりません。たくさんのデータを作り、時間をかけた学習が必要になります。
この記事では、物体検出のデータ作成ツールの中で最も簡単な「VIA」の使い方を紹介します。
もう一つのツール「COCO Annotator」の使い方はこちら。
アノテーションとは
画像AIの学習には1度に2種類のデータが必要です。そのうちの一つにアノテーションデータがあります。
- 画像データ = 対象物が写っている画像群。jpgファイルが最も使われている。
- アノテーションデータ = 画像の中の何を検出したいか位置や分類を示したファイル。AIモデルによって必要な形式が異なるが、json形式が多い。全ての画像のアノテーションを1つのファイルにまとめるのが一般的。
アノテーションはラベリングともいいます。
そして、学習する全ての画像とアノテーションデータをまとめてデータセットと呼びます。
アノテーションの形式
画像処理AIのモデルには大きく2つあり、必要なアノテーションデータが違います。
- 分類モデル = 画像自体を何に分類すればいいかラベルを付ければよいため、画像対ラベル、の形をテキストで書いて作成する。
- 物体検出モデル = 画像内のどの物体を検出するか示す必要があるため、ツールを使ってマーキングしつつ分類も示す。
この記事では、物体検出のアノテーションを解説します。物体検出のアノテーションデータには複数の形式があります。
- Pascal VOC形式 = xmlファイル。SSDモデルなどで利用される。
- MS-COCO形式 = jsonファイル。最近のモデルで利用される。
- その他モデル固有の形式 = txtファイル。分類モデル、YOLOモデルなどで利用される。
使用するAIモデルに合った形式が必要ですが、変換ツールが出回っているため(VOC⇔COCO、COCO→YOLOなど)あまり問題になりません。
「VIA」の利用方法
アノテーションツールはいくつかありますが、筆者が最も簡単と感じる「VIA」の使い方を紹介します。
ダウンロード
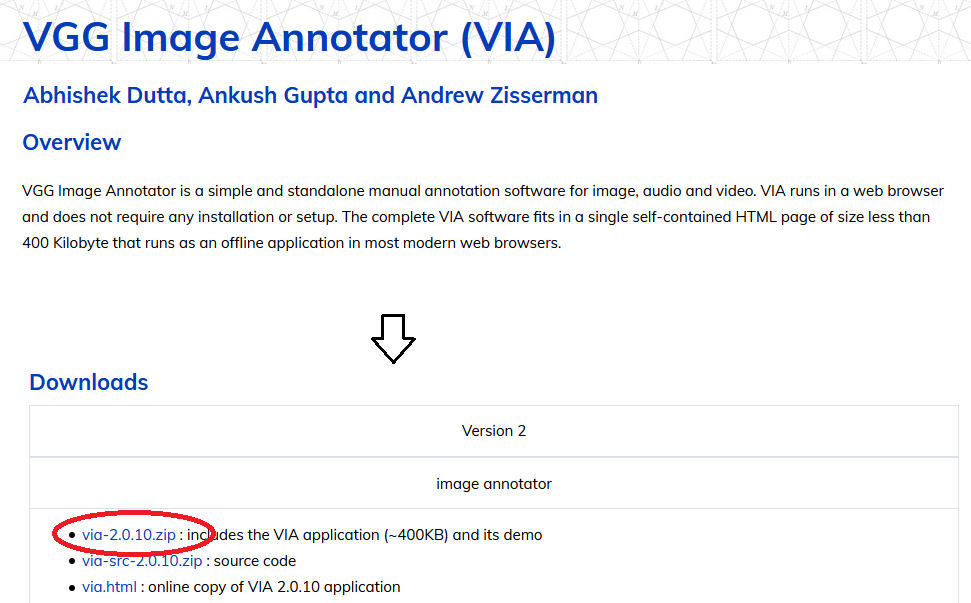
1.下記にアクセスし、version2をダウンロードしてください。WindowsもMacintoshも同じです。
http://www.robots.ox.ac.uk/~vgg/software/via/
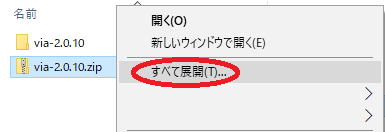
2.ダウンロードしたzipファイルを解凍してください。選択して右クリック→「全て展開」です。
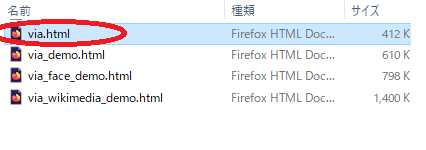
3.解凍したフォルダの中の「via.html」をダブルクリックするとブラウザが開き、VIAが利用できます。
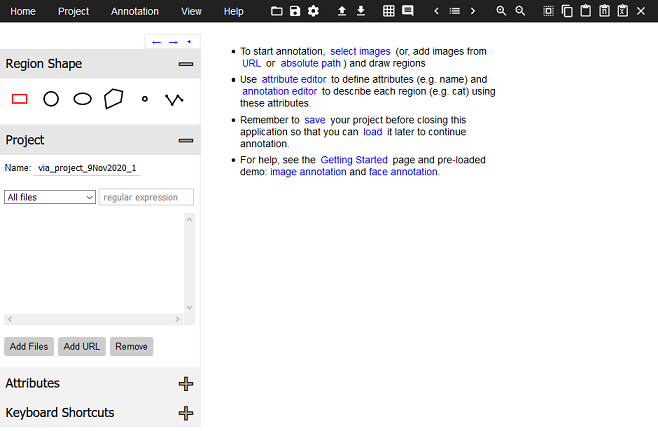
初期設定
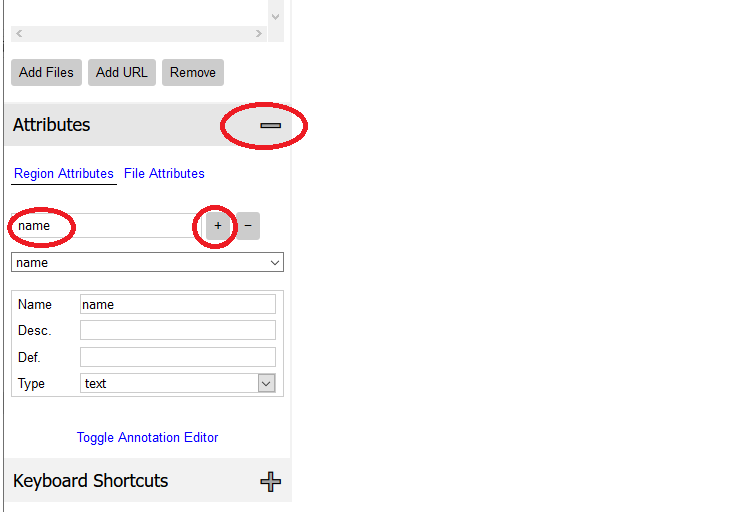
4.左メニューのAttributesの「+」ボタンを押し、「name」と入力し「+」を押します。
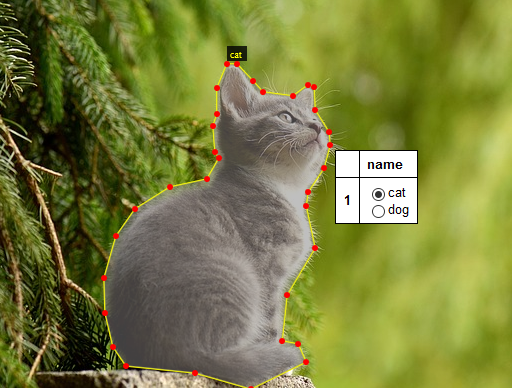
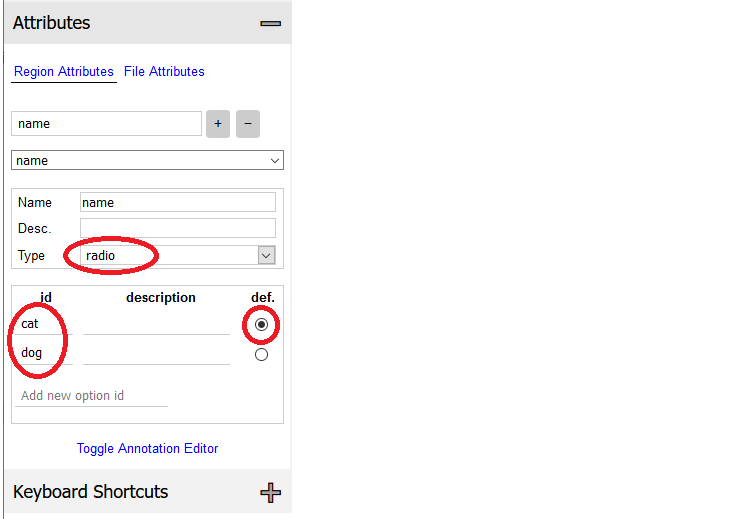
5.「Type」に「radio」を選択し、「id」に検出物の分類名を入力して「Enter」を押します。例は動物を検出したいため cat や dog を入力しています。この検出物のパターンを「クラス」または「カテゴリ」と呼びます。「def.」は指定してもしなくてもいいです。
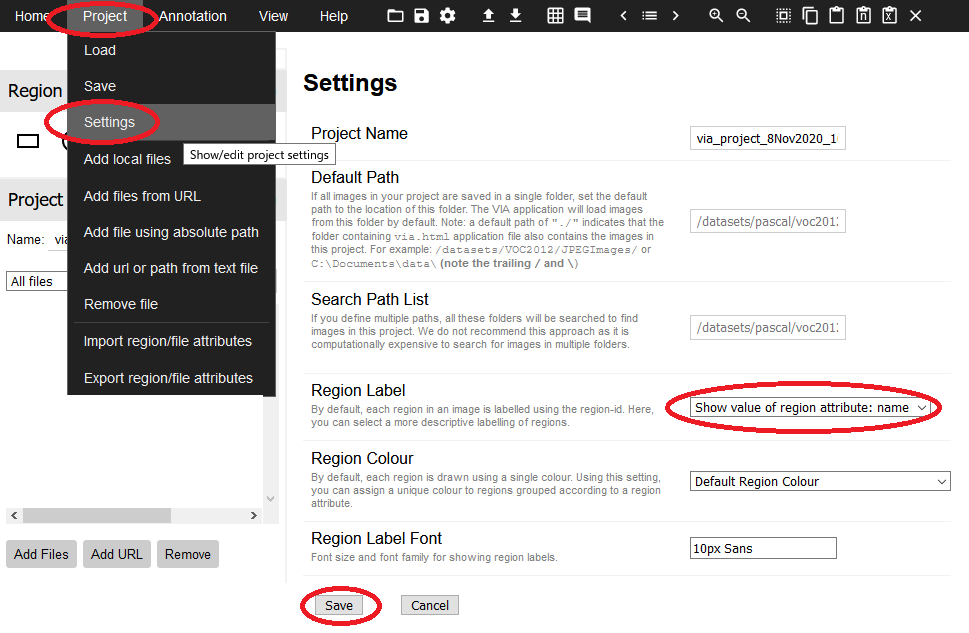
6.上メニューの「Project」→「Settings」を実行し、「Region Label」に「Show value of region attribute : name」を選択し、「save」を押します。
画像を開く
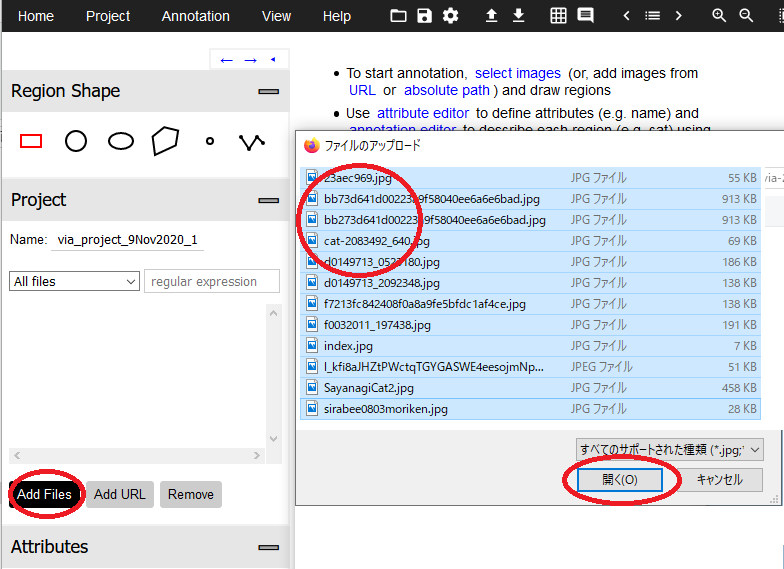
7.左メニューの「Add Files」を押し、「ファイルのアップロード」ウィンドウでアノテーションしたい画像を複数選択し、「開く」を押します。
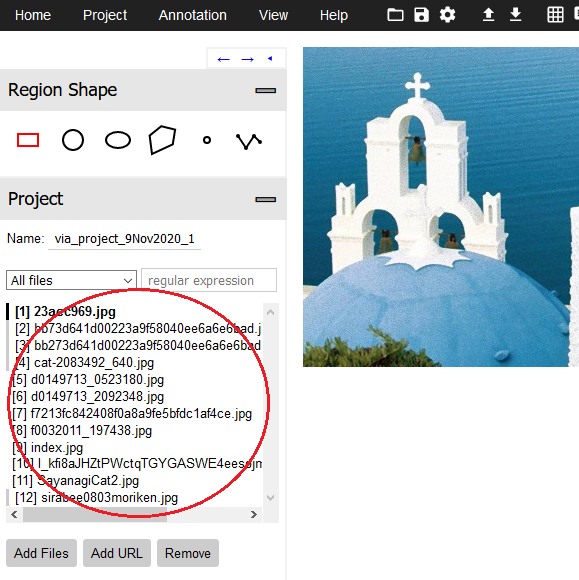
8.画像が読み込まれてファイル一覧が表示されます。
アノテーションを行う
<BOX型物体検出のデータを作る場合>
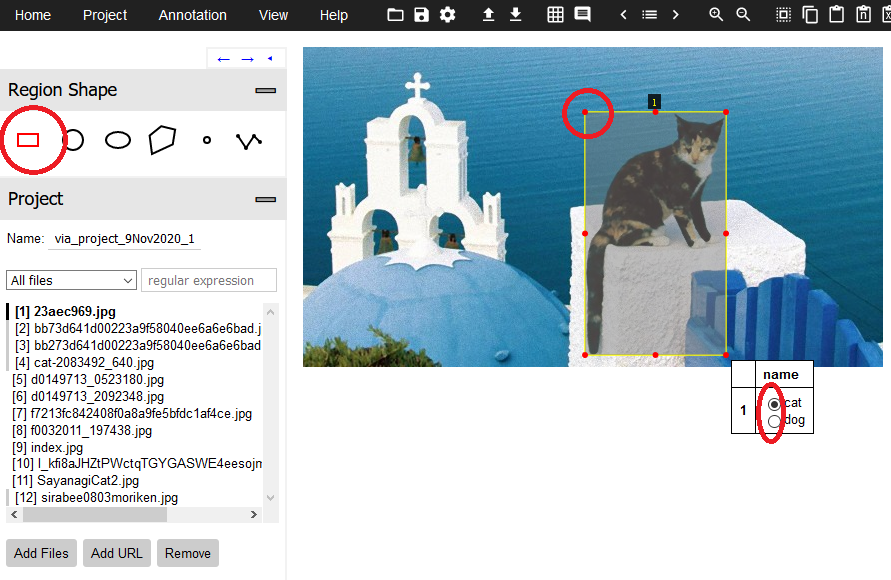
9.「Region Shape」で四角形「Rectangular」を選択し、対象物をドラッグして四角形で囲みます。囲んだ後、クラスを選択します。
<セグメンテーション型物体検出のデータを作る場合>
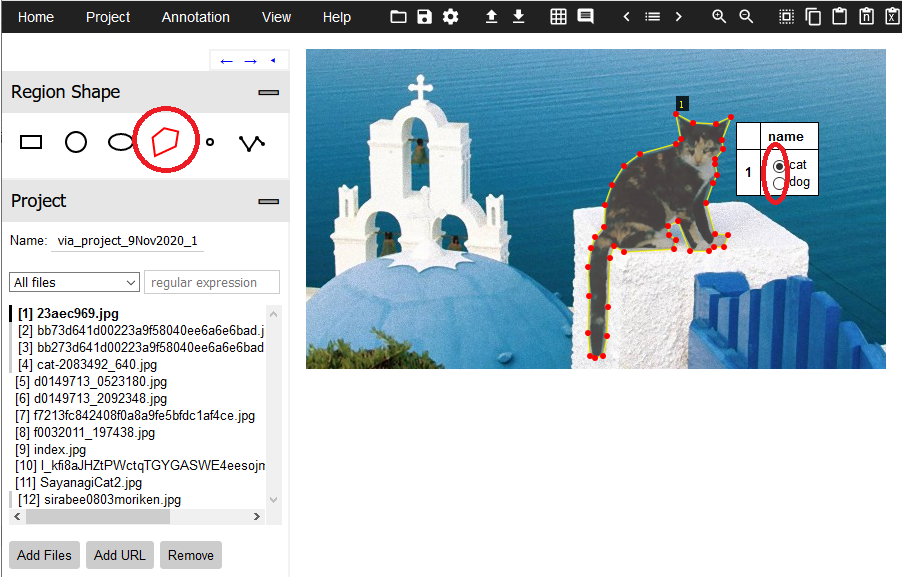
9.「Region Shape」で五角形「Polygon」を選択し、対象物を囲むようにクリックを重ねます。「Enter」を押すと領域が確定します。その後、クラスを選択してください。
10.次の画像名をクリックして、これを繰り返します。
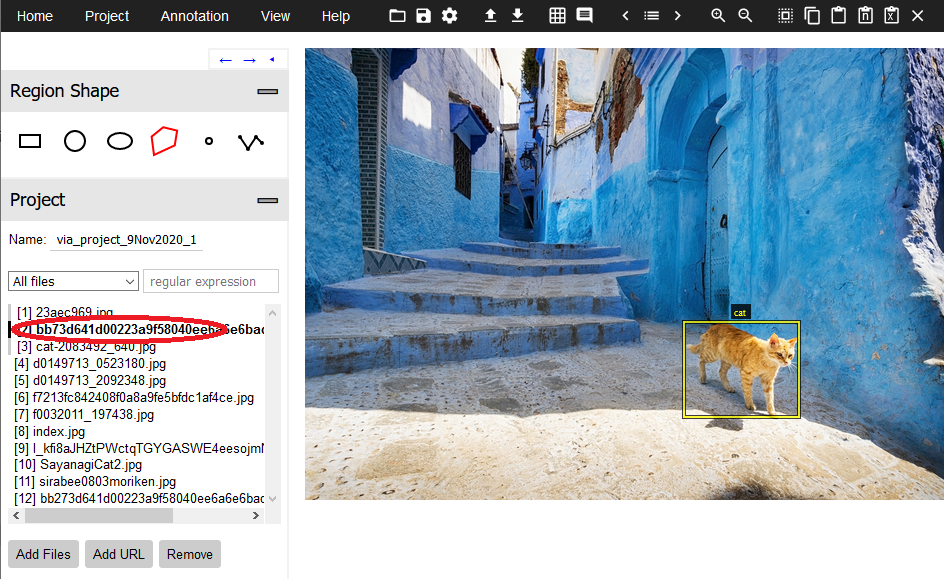
保存
11.作業したアノテーションデータを保存する時は、上メニューから「Annotation」→「Export Annotation COCO format」を実行します。

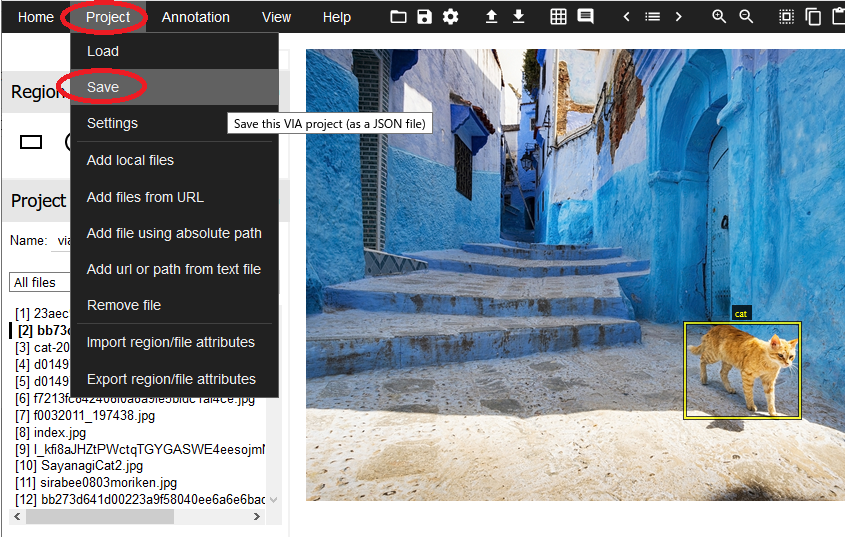
12.アノテーションデータだけでなく、全ファイルの状態を保存したい場合は、「Project」→「Save」を実行、次の画面はそのまま「OK」を押してください。VIAを閉じて再開する時に、このファイルを「Load」すれば作業が再開できます。
変換
13.上で保存したアノテーションデータはMS-COCO形式です。モデルによってはPascalVOC形式が必要かもしれません。その時は下記のようなツールを使って変換してください。この他の形式に関しても変換ツールは探せばあります。
Convert COCO to VOC
https://gist.github.com/jinyu121/a222492405890ce912e95d8fb5367977
モデルの学習に使う
14.モデルによって学習時のファイル配置が決まっているので、説明を読んでその通りにしてください。一般的にはこのようなフォルダ構成で配置します。

アノテーションの解説とツールの使い方は以上です。
画像処理AIは「畳み込み」を行う性質上、正確なアノテーションをしても多少甘い検出になります(輪郭が丸まります)。
しかし地道にデータを増やし、学習時間を増やし、正確なアノテーションをすることで次第に物体の輪郭に沿った検出をすることができます。
職場によってはアノテーション作業を外注することがあるかもしれません。それでもAIの精度に関わってくるため、いい加減な作業がされていないかチェックすることをおすすめします。