

この記事では、AIを作ってみよう:画像分類CNN(2/3) で作ったAIを解説していきます。
プログラムを簡単に解説
作ったプログラムをパートに分けてみます。
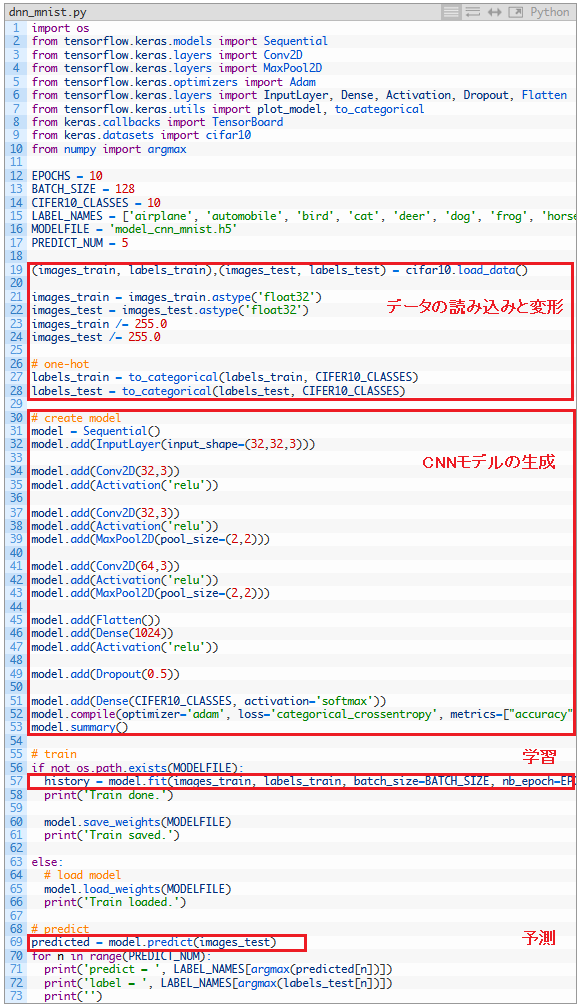
最初のパートでは、データを読み込んだ後、学習をするための変形をしています。
物体名を「0,0,1,0,0,0,0,0,0,0」といった0/1の数値にします。順番に並べた時の場所を表しています。これをベクトル化(one-hotベクトル化)といい、学習するに都合のよい形となります。
次のパートでは、CNNモデルを生成しています。kerasライブラリを用いて、層を重ね、結果、下のような構成にしています。

Convとは畳み込み層のことで、これがCNNの特徴です。大きなサイズのデータを圧縮することによって、全体の特徴を捉える効果があります。
Poolとはプーリング層のことで、全体の特徴を消さずに圧縮する層です。計算を早くする役割と、物体が中心からずれていても認識できるような効果があります。
後半にDense層がありますが、1つ目のDenseは特徴を記憶する役割があって、大きくするほど複雑な特徴を記憶します。最後のDenseは全結合といってデータをまとめて数値とする層です。こうして最後の数値、今回は物体10種類の各確率を出します。
Dropout層は、ここでは詳しく述べませんが、Conv層のどれかをランダムに無効化することによって、違うモデルを作り出すような役割があります。これによりモデルの精度が上がります。
3つ目のパートでは、学習データをCNNモデルに入力し学習をさせています。fitという命令1行でできてしまうんですね。
最後のパートで、predictという命令を用いて学習済みモデルにテストデータを入力し、予測をさせています。予測の結果は最初の5つだけ取り出し、表示させています。
さて、
どうして「畳み込み」のようなことをするの? -> スマホで写真を指でピンチ(縮小)すると全体像が把握できますよね。それと同じような感覚で、全体の特徴をとらえることをしています。
どうして「プーリング」のようなことをするの? -> カメラの手振れ補正機能のようなものです。物体が少しぐらいずれていても認識できるようにします。
どうし -> ええい、正直言うと、視神経を真似て作ってみたらうまくいったんです!
今回はざっくりの説明に留めました。
CNNはデータを圧縮しながら特徴をとらえることによって、大きく複雑なデータを認識できるようにしているのですね。人間の目もこのように働いているというのは本当です。