
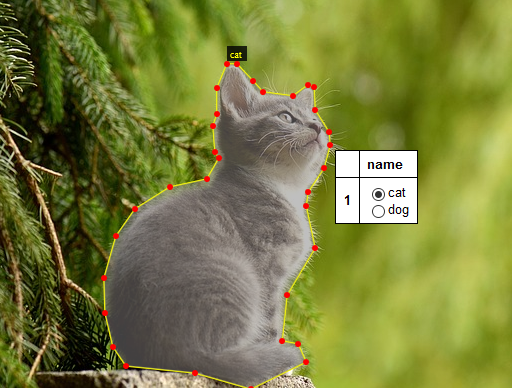
AIによる物体検出は、学習済みのAIをダウンロードすることによって簡単に体験することが可能です。
しかし特殊な物体を検出したい場合は、自分でデータを作り学習を行わなければなりません。大量のデータで時間をかけた学習が必要になります。
この記事では、物体検出のデータ作成ツールの中でも万能な「COCO Annotator」の使い方を紹介します。
アノテーションとは
画像AIの学習には1度に2種類のデータが必要です。そのうちの一つにアノテーションデータがあります。
- 画像データ = 対象物が写っている画像群。jpg, pngといったファイル形式。
- アノテーションデータ = 画像の中の何を検出したいか位置座標や分類を付与(アノテーション)し、それを保存したファイル。AIモデルによって必要な形式が異なる。
アノテーションはラベリングともいいます。
そして、学習する全ての画像とアノテーションデータをまとめてデータセットと呼びます。
アノテーションの形式
画像検出AIのモデルには大きく2つあり、必要なアノテーションデータが違います。
- 分類モデル = 画像自体を分類する。ラベルデータは各画像に1ラベルを付ければよいため、「画像 対 ラベル」の形でテキストファイルへ書いて作成する。
- 物体検出モデル = 画像内の物体の位置を検出し分類する。アノテーションデータは画像内のどの物体を検出するか示す必要があるため、ツールを使ってマーキングしつつ分類も付与する。
- BOX検出型 = 物体を四角で囲って検出する。アノテーションデータも四角で囲う形で作成する。
- セグメンテーション検出型 = 物体の輪郭通りに検出する。アノテーションデータも物体の輪郭に沿って囲う必要がある。
この記事では、2つ目の物体検出モデルのアノテーションを解説します。
物体検出のアノテーションデータには複数のファイル形式があります。
- Pascal VOC形式 = xmlファイル。SSDモデルなどで利用される。
- MS-COCO形式 = jsonファイル。比較的後発のモデルで利用される。
- その他モデル固有の形式 = txtファイル。分類モデル、YOLOモデルなどで利用される。
使用するAIモデルに合った形式が必要ですので確認しましょう。変換ツールも出回っています(VOC⇔COCO、COCO→YOLOなど)。
「COCO Annotator」の使い方
アノテーションツールはいくつかありますが、中でも万能な「COCO Annotator」の使い方を紹介します。
動作環境
COCO Annotatorは下記の環境で動作します。
- OS:Linux + Docker
- 言語:Python
- メモリ:大きいほどよいです。多くの画像を作業しているとメモリ不足になることがあります。
インストール
1.LinuxにDockerをインストールしていない場合はインストールしてください。
2.Linux上で下記のように実行し、セットアップしてください。
- git clone https://github.com/jsbroks/coco-annotator
- cd coco-annotator
- vi docker-compose.yml
webserver-stable,workers-stable の記述を -> webserver-latest,workers-latest へ変更
起動
3.次のように実行してCOCO Annotatorを起動します。
- docker-compose up
しばらくするとローカルPCでCOCO Annotatorのプロセスが起動します。このままでは画面は見えません。
4.ブラウザを起動してURLを次のように入力し、COCO Annotator にアクセスします。
http://localhost:5000/
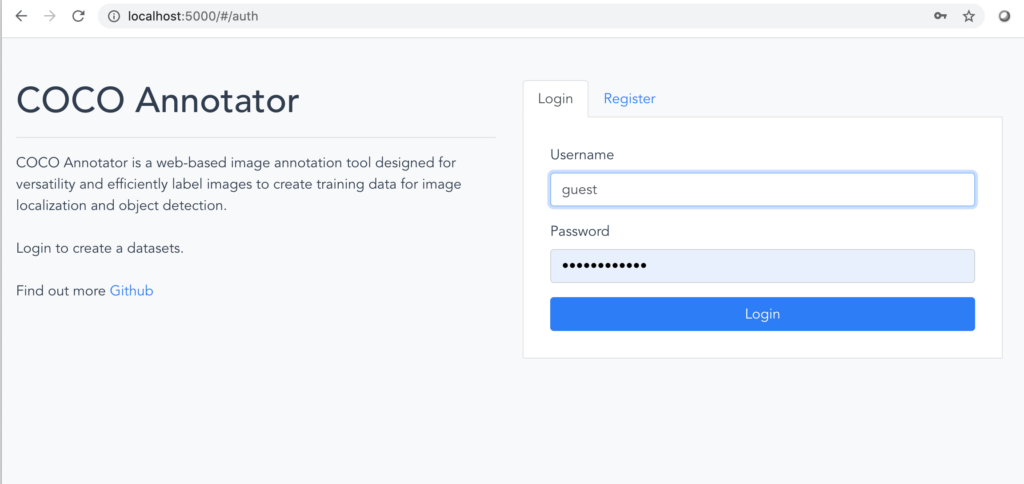
5.適当なユーザ名を登録をしてログインします。
※ 反応がなかったり実行時にエラーが出る場合は、次のように再起動を試してください。
- docker-compose stop
- docker volume rm coco-annotator_mongodb_data
- docker-compose up
カテゴリの登録
6.「Categories」タブの 「Create」ボタンをクリックし、「Category Name」に自分で命名したカテゴリ名を入力、「Create Category」ボタンをクリックします。
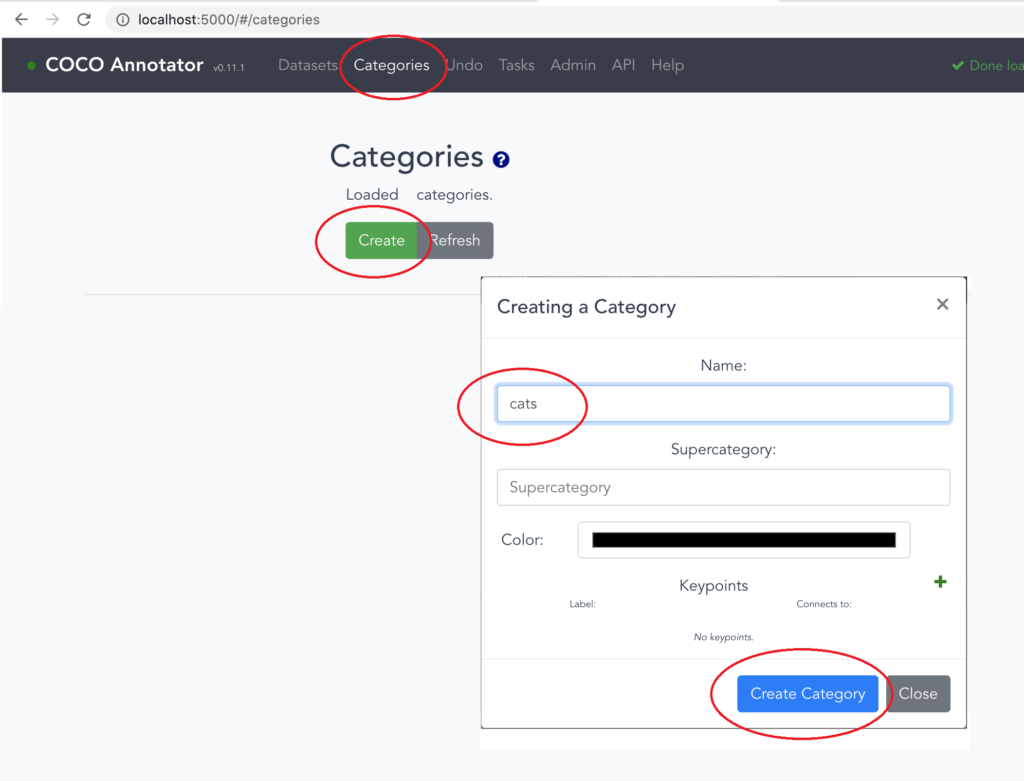
7.上記を繰り返し、分類の数だけカテゴリーを作成します。
画像の読み込み
8.「Datasets」タブに移り、「Create」ボタンをクリックし、任意のデータセット名を「Dataset Name」に入力。「Default Categories」に作成したカテゴリーをすべて選択し、「Create Dataset」ボタンをクリックします。
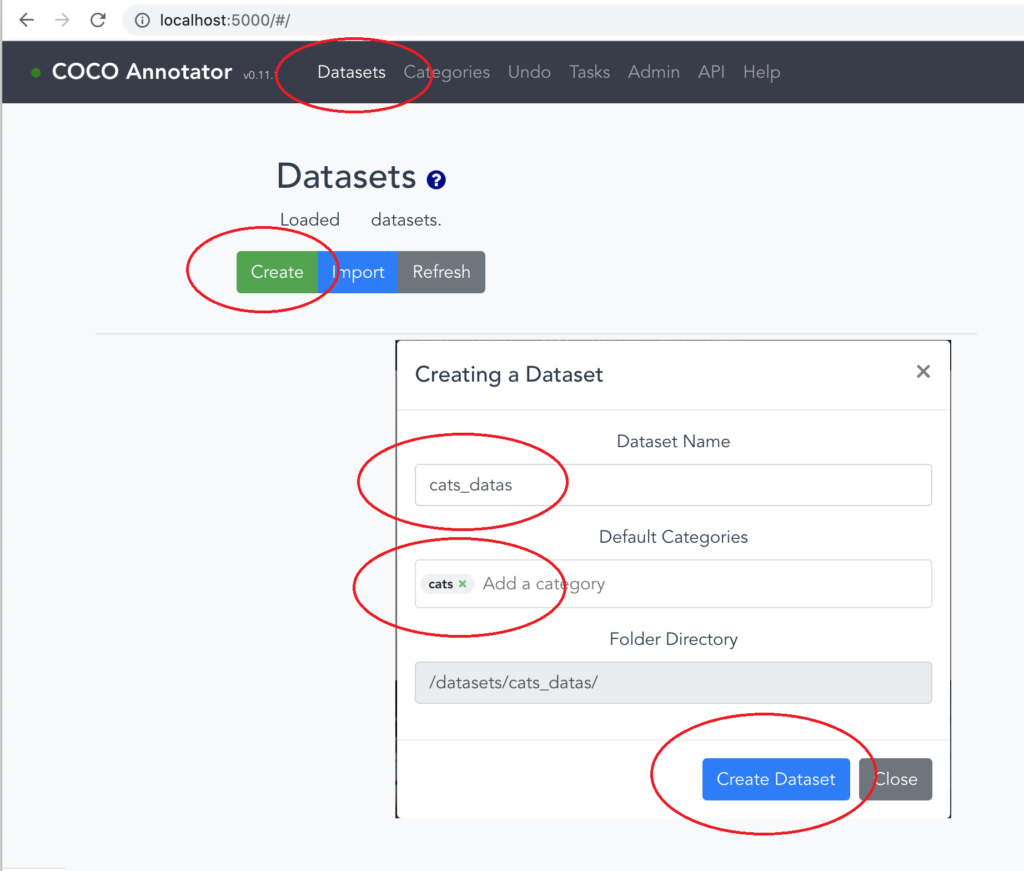
9.COCO Annotatorをインストールしたフォルダに「datasets/データセット名」というフォルダができているので、その中にアノテーションしたい画像を全て入れます。画像の拡張子は小文字にしないと認識しないことがあります(.jpg等)。
10.しばらくすると画像が読み込まれるので、作成した Datasets を開き直し、認識されていることを確認します。
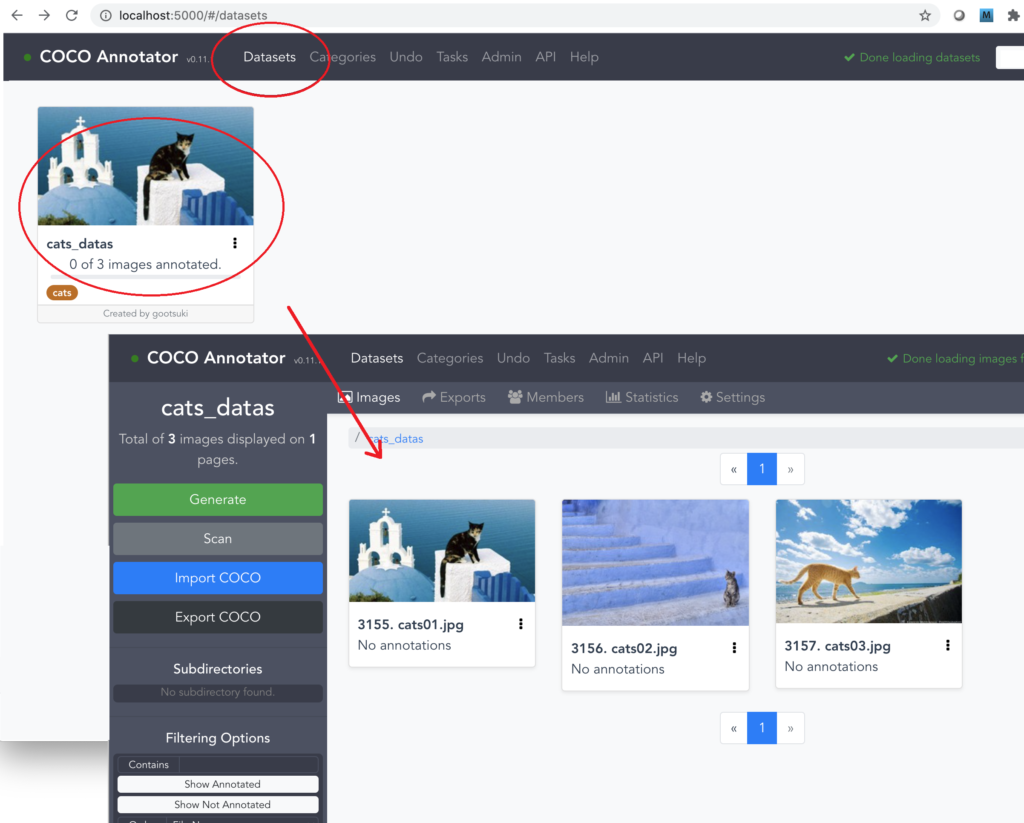
※ 画像が読み込まれない場合は、対象のデータセット画面で「Scan」ボタンを押してしばらく待ち開き直してください。それでも読み込まれない場合は、前述したCOCO Annotatorの再起動を試みてください。
アノテーション作業
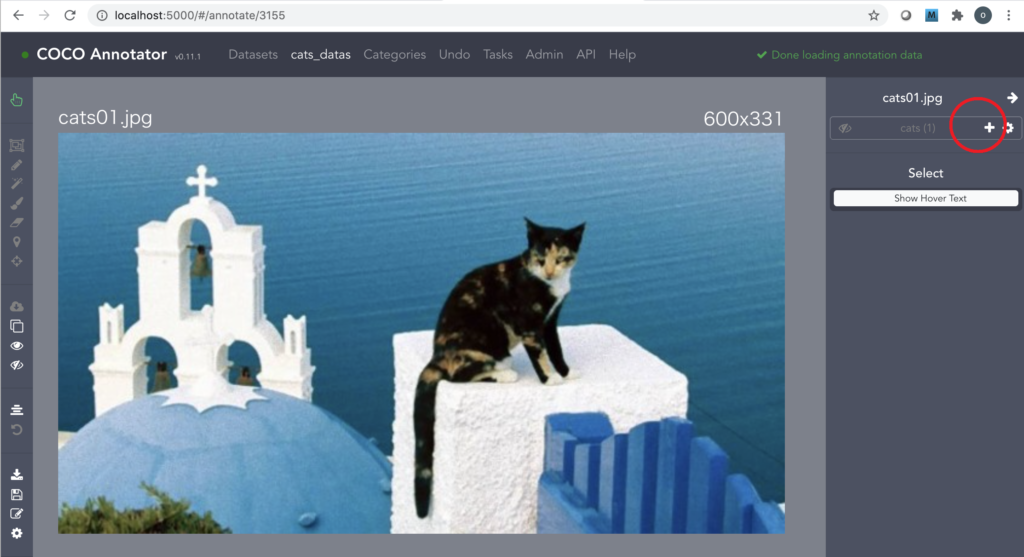
11.画像を1枚選択すると、右側に「Category」が表示されます。該当するカテゴリの「+」をクリックすると「id」が作成され、アノテーションを開始できます。表示される色はAI実行には無関係なため気にしないでください。
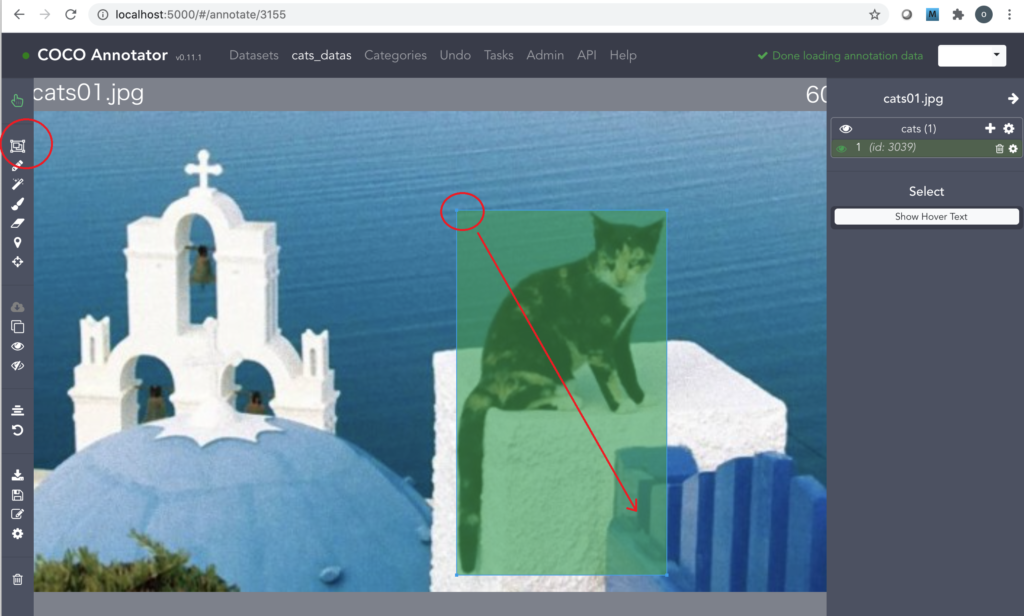
<BOX型物体検出用のアノテーションを行う場合>
12.画面左側の「BBox」アイコンを押し、対象物をドラッグして四角で囲みます。
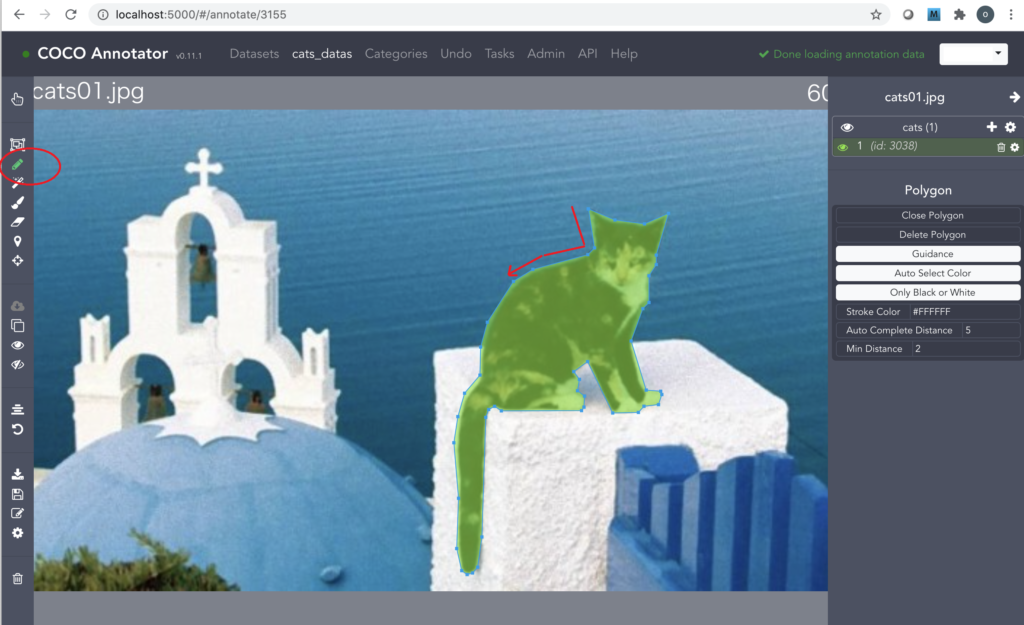
<セグメンテーション型物体検出用のアノテーションを行う場合>
12.画面左側の「Polygon」アイコンを押し、ポイントしながら対象物を囲みます。マウスのホイールを使って画像の拡大・縮小を行うと便利です。最後の終点は始点に正確に重ねないと完了できません。
13.画像内に複数の物体をアノテーションしたい場合は、「+」ボタンを押し繰り返します。
14.画面右側の矢印を押して、次の画像へ移ります。
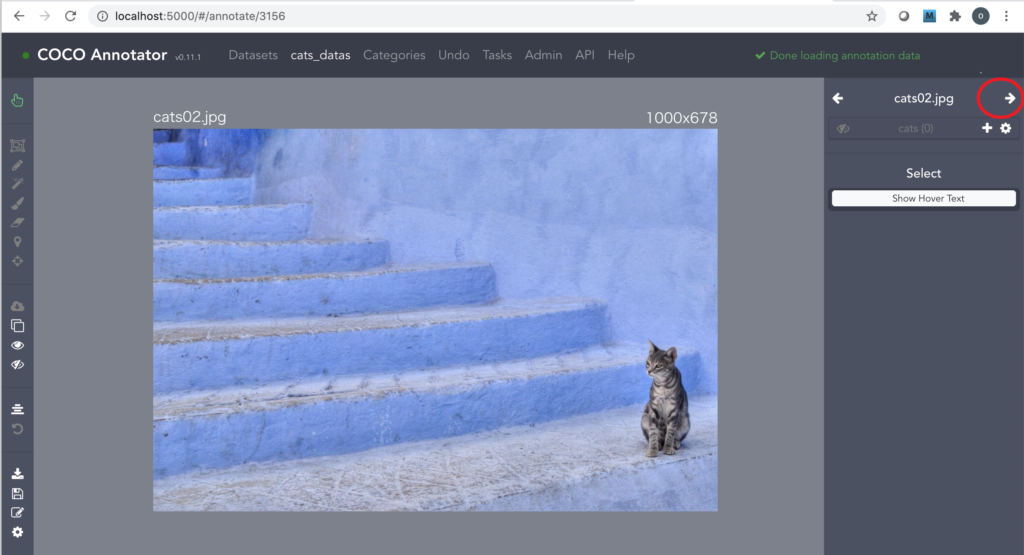
※ アノテーションの削除・修正は画面左側の Eraser Tool や「↺」を利用します。
※ Undo タブをクリックすると、操作履歴が分かり、復元が可能です。フォルダの作り直しなどはここで完全削除する必要があります。
※ 1枚の画像の中で同じカテゴリの物体が複数ある時、異なる「id」でアノテーションして学習することができます。各個体を区別して検出したい場合に使われ、インスタンスセグメンテーションといいます。これに対し同じ「id」で複数の物体をアノテーションした場合は個体を区別せず、セマンティックセグメンテーションとなります。後者は大きな検出BOX領域の中に複数の物体があるような形で学習されます。筆者は検出BOXが同一であると困る場面があり、前者を使うことが多いです。
保存
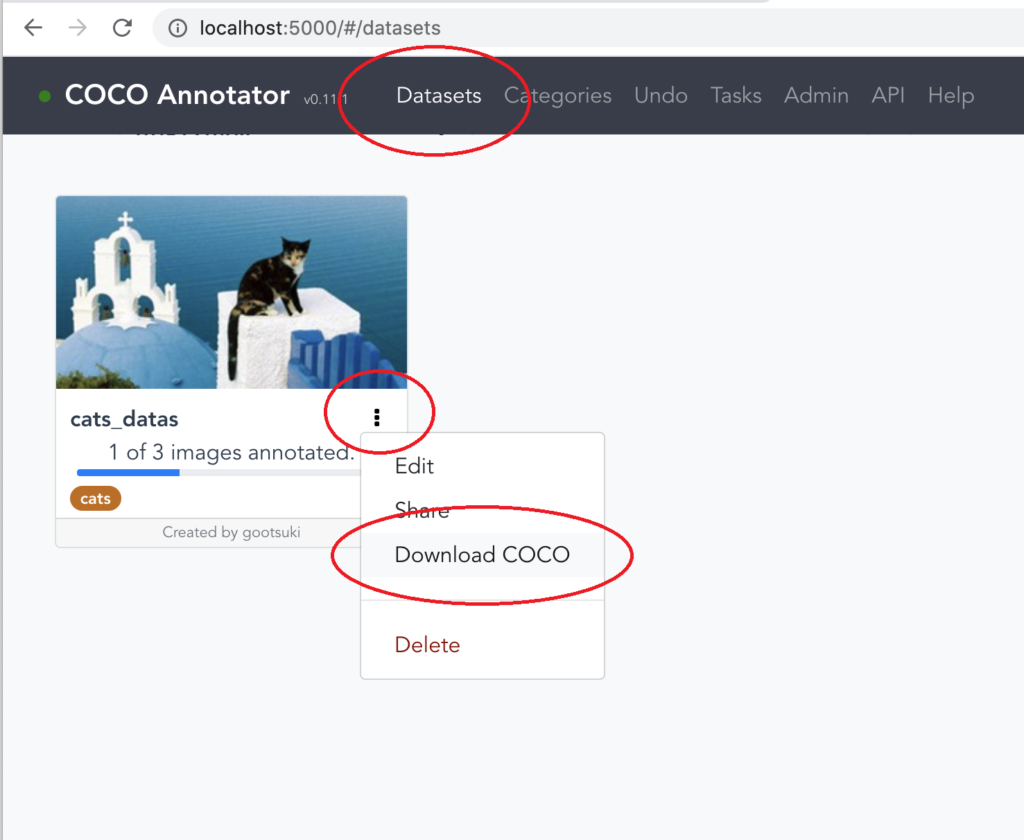
15.「Datasets」 タブをクリックし、対象データセットの「︙」から「Download COCO」を選択すると、データセット全体のjsonファイルが生成されます。
変換
16.上で保存したアノテーションデータはMS-COCO形式です。モデルによってはPascalVOC形式が必要かもしれません。その時は下記のようなツールを使って変換してください。
Convert COCO to VOC
https://gist.github.com/jinyu121/a222492405890ce912e95d8fb5367977
モデルの学習に使う
17.モデルによって学習時のファイル配置が決まっています。説明を読んでその通りにしてください。一般的にはこのようなフォルダ構成で配置します。

アノテーションの解説とツールの使い方は以上です。
画像処理AIは「畳み込み」を行う性質上、正確なアノテーションをしても多少甘い検出になる(輪郭が丸まる)ことがあります。
しかし地道にデータを増やし、学習時間を増やし、正確なアノテーションをすることで次第に物体の輪郭に沿った検出をすることができます。
職場によってはアノテーション作業を外注することがあるかもしれませんが、AIの精度に関わってくるため、いい加減な作業がされていないかチェックすることをおすすめします。